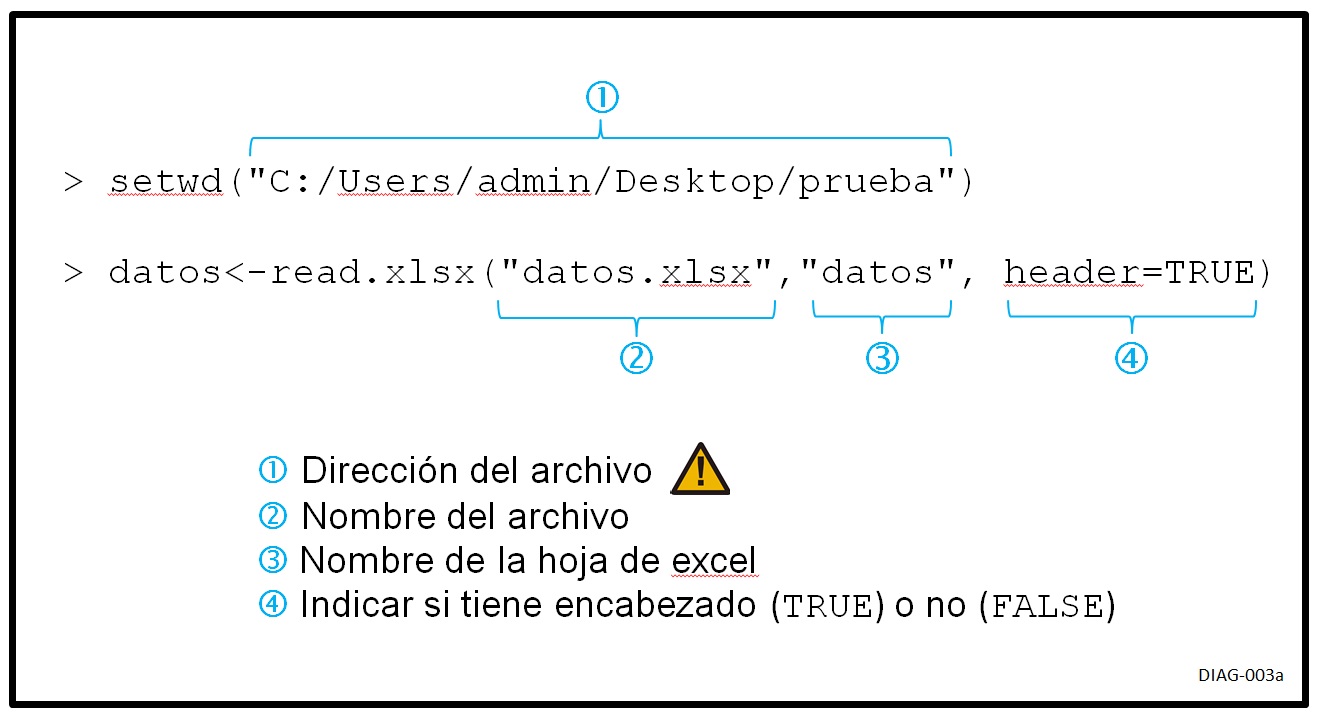
### Verificación de supuestos ###
resi<-residuals(MOD)
stdresid<-rstandard(MOD)
#par(mfrow=c(2,2))
#plot(MOD)
#shapiro:Para normalidad
#Ho:Hay normalidad
#Ha:No hay normalidad
#shapiro.test(rnorm(100,0,1))
shapiro.test(resi) #Si son normales los residuos
#Kolmogorov-Smirnov: Para normalidad
#Ho:Hay normalidad (No hay diferencia significativa entre la distribucion evaluada y una distribucion normal)
#Ha:No hay normalidad (Si hay diferencia significativa entre la distribucion evaluada y una distribucion normal)
#prueba<-rnorm(100,0,1)
#ks.test(prueba,"pnorm",mean=mean(prueba), sd=sd(prueba))
ks.test(resi,"pnorm",mean=0, sd=sd(resi))
#Barlett: Para homogeneidad de varianzas
with(tabla, tapply(ESP_NUC_PROC, LOTE, var, na.rm=TRUE))
bartlett.test(ESP_NUC_PROC ~ LOTE, data=tabla)
#Aca necesariamente toca poner la variable que
#se esta analizando y los grupos, tal cual como esta escrito
#en el modelo arriba
with(tabla, tapply(ESP_NUC_PROC, LOTE, var, na.rm=TRUE))
leveneTest(ESP_NUC_PROC ~ LOTE, data=tabla, center="median")
#En el test de Levene, se puede centrar por mediana o por promedio
with(tabla, tapply(ESP_NUC_PROC, LOTE, var, na.rm=TRUE))
leveneTest(ESP_NUC_PROC ~ LOTE, data=tabla, center="mean")
### Falta el test de aleatoriedad - No-paramétrico
bartlett.test(resi~MOD)
resi<-residuals(MOD)
stdresid<-rstandard(MOD)
#par(mfrow=c(2,2))
#plot(MOD)
#shapiro:Para normalidad
#Ho:Hay normalidad
#Ha:No hay normalidad
#shapiro.test(rnorm(100,0,1))
shapiro.test(resi) #Si son normales los residuos
#Kolmogorov-Smirnov: Para normalidad
#Ho:Hay normalidad (No hay diferencia significativa entre la distribucion evaluada y una distribucion normal)
#Ha:No hay normalidad (Si hay diferencia significativa entre la distribucion evaluada y una distribucion normal)
#prueba<-rnorm(100,0,1)
#ks.test(prueba,"pnorm",mean=mean(prueba), sd=sd(prueba))
ks.test(resi,"pnorm",mean=0, sd=sd(resi))
#Barlett: Para homogeneidad de varianzas
with(tabla, tapply(ESP_NUC_PROC, LOTE, var, na.rm=TRUE))
bartlett.test(ESP_NUC_PROC ~ LOTE, data=tabla)
#Aca necesariamente toca poner la variable que
#se esta analizando y los grupos, tal cual como esta escrito
#en el modelo arriba
with(tabla, tapply(ESP_NUC_PROC, LOTE, var, na.rm=TRUE))
leveneTest(ESP_NUC_PROC ~ LOTE, data=tabla, center="median")
#En el test de Levene, se puede centrar por mediana o por promedio
with(tabla, tapply(ESP_NUC_PROC, LOTE, var, na.rm=TRUE))
leveneTest(ESP_NUC_PROC ~ LOTE, data=tabla, center="mean")
### Falta el test de aleatoriedad - No-paramétrico
bartlett.test(resi~MOD)