Go to Blogger edit html and find these sentences.Now replace these sentences with your own descriptions.

Go to Blogger edit html and find these sentences.Now replace these sentences with your own descriptions.

Go to Blogger edit html and find these sentences.Now replace these sentences with your own descriptions.

Go to Blogger edit html and find these sentences.Now replace these sentences with your own descriptions.

Análisis univariado y multivariado, pruebas de comparación, Diseño experimental, Control de CAlidad, Quality by Design
### Ingreso de datos ###
# 1. Se puede ingresar los datos directamente, así:
x=c(499.3361, 500.3681, 501.2236, 498.3309, 499.0955, 501.4942, 500.3857, 499.7793, 499.7361, 502.3487, 499.6574, 500.1297, 500.2847, 498.2438, 498.8386, 499.5641, 498.9991, 499.7621, 500.6080, 499.1800, 500.2351, 499.6674, 499.2542, 500.6901, 500.8001, 499.7816, 500.0355, 500.6031, 501.2470)
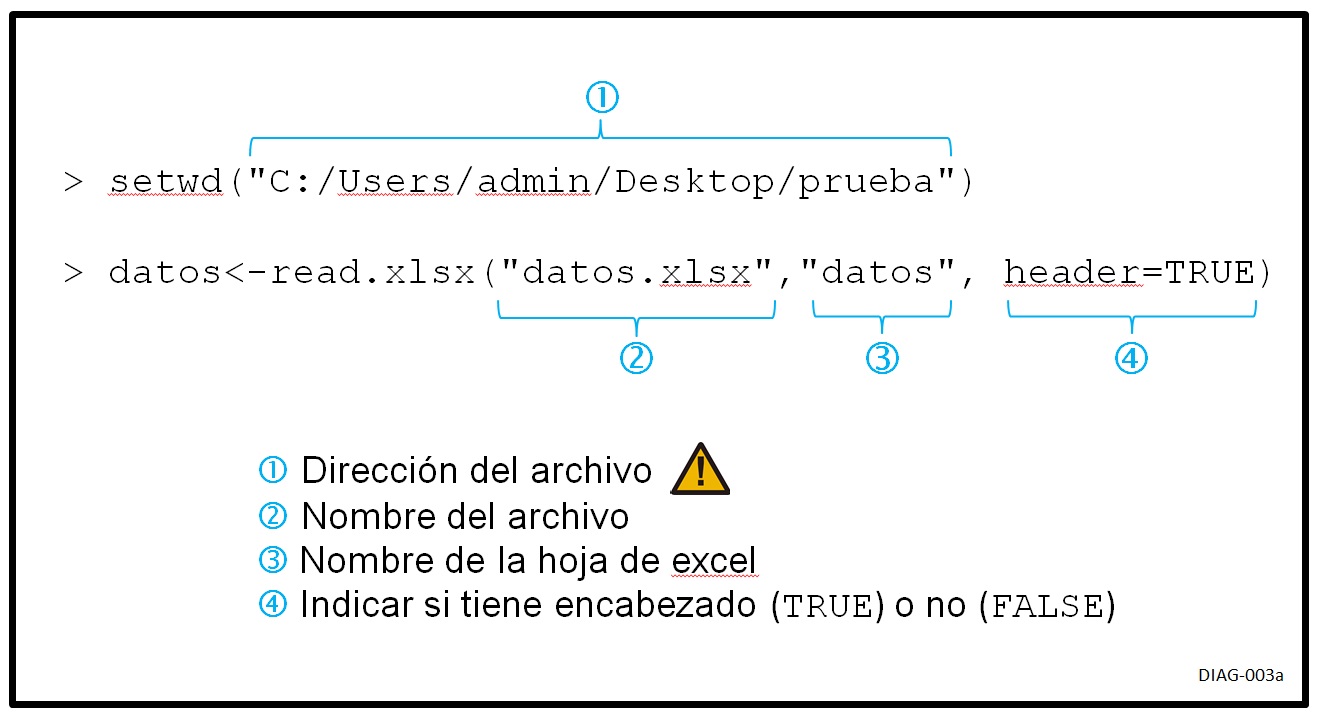
# 2. Se puede ingresar los datos, tomados directamente de archivos de excel, así:
# En este caso se requieren las siguientes librerias: (xlsx), (rJava),(xlsxjars)
setwd("C:/Users/admin/Desktop/prueba")
datos<-read.xlsx("datos.xlsx","datos", header=TRUE)


# 1. Se puede ingresar directamente del enlace de internet, así:datos<-read.table ("http://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data",sep=",")
Individuo
|
UFC
|
UFC
|
(T
= 0min)
|
(T
= 10min)
|
|
1
|
6
|
2
|
2
|
1
|
0
|
3
|
11
|
9
|
4
|
0
|
0
|
5
|
2
|
1
|
6
|
0
|
1
|
7
|
1
|
3
|
8
|
0
|
0
|
9
|
4
|
0
|
10
|
0
|
0
|
Ho :
|
No hay diferencia estadísticamente significativa entre el número de UFC, antes y después de la aplicación del gel antibacterial.
|
Ha :
|
El número de UFC es menor después de la aplicación del gel antibacterial
|
No.
Muestra
|
Met.
1
|
Met.
2
|
1
|
2,30
|
2,07
|
2
|
1,61
|
1,73
|
3
|
2,65
|
2,88
|
4
|
1,38
|
1,15
|
5
|
2,42
|
2,30
|
6
|
1,73
|
1,50
|
7
|
2,76
|
2,65
|
8
|
2,30
|
2,42
|
9
|
2,19
|
1,96
|
Ho :
|
No hay diferencia estadísticamente
significativa entre la metodología 1 y la metodología 2.
|
Ha :
|
No hay diferencia estadísticamente significativa entre la
metodología 1 y la metodología 2.
|